핵심요약
이 글은 Amazon SageMaker AI 환경에서 GPT-OSS 120B 모델을 활용한 LLM 추론 성능 테스트와 GPU 용량 산정 방법을 다룹니다. vLLM과 SGLang 프레임워크를 사용하여 다양한 워크로드 시나리오에서 성능을 비교 분석하고, LLM 추론의 최적화 기법과 주요 성능 지표를 설명합니다.
SageMaker AI 기반 GPT-OSS 추론 성능 테스트 및 용량 산정 요약
LLM 추론 메커니즘 및 최적화
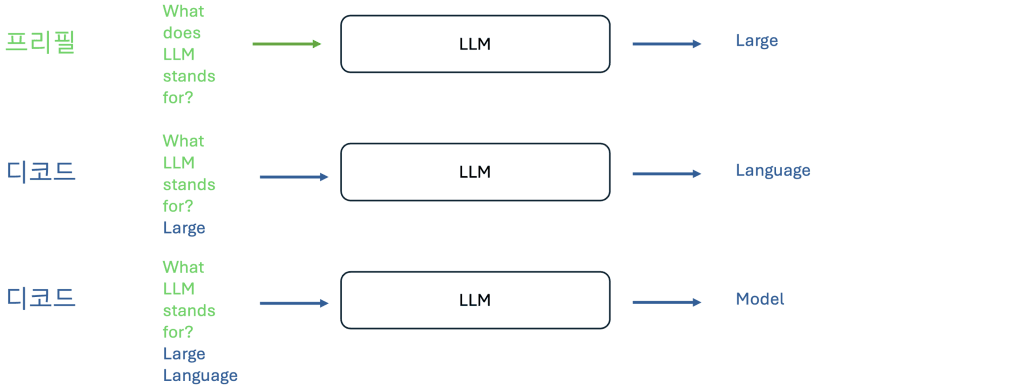
- LLM 추론은 프리필(Prefill) 및 디코드(Decode) 두 단계로 구성되며, 프리필은 병렬 행렬-행렬 연산으로 KV 캐시를 생성하고, 디코드는 자기회귀적 순차 연산으로 토큰을 생성합니다.
- 디코드 단계는 메모리 대역폭 바운드(memory-bandwidth bound) 특성을 가지며, 키-값 캐시(KV Cache) 관리는 불필요한 데이터 전송 및 재계산을 최소화하여 효율성을 극대화합니다.
- **연속 배치 처리(Continous Batch)**는 완료된 시퀀스 슬롯에 즉시 새로운 시퀀스를 추가하여 GPU 활용도를 높이고, **페이지드 어텐션(Paged Attention)**은 가상 메모리 페이징 기법을 활용해 키-값 캐시 메모리 단편화를 방지하고 효율적으로 관리합니다.
- **분산 비분리 프리필링(Disaggregated Prefilling)**은 프리필과 디코드 단계를 물리적으로 분리하여 처리량을 개선하며, 하드웨어 가속은 CUDA 커널 최적화 및 연산 융합을 통해 성능을 높입니다.
추론 성능 지표 및 오픈소스 프레임워크
- 주요 지연 시간(Latency) 지표로는 TTFT (Time To First Token), ITL (Inter Token Latency), TPOT (Time Per Output Token), **E2E (End To End Latency)**가 있습니다.
- 처리량(Throughput) 지표는 TPS (Token Per Second) 및 **RPS (Request Per Second)**가 주로 사용되며, Goodput은 서비스 수준 목표를 충족하는 요청의 처리량을 측정합니다.
- vLLM과 SGLang은 대표적인 오픈소스 LLM 추론 프레임워크로, 프리픽스 캐싱 및 연속 배치 처리 등 다양한 최적화 기법을 적용하여 성능을 지속적으로 개선하고 있습니다.
- vLLM은 V1 아키텍처를 통해 통합 스케줄러, 청크드 프리필(Chunked Prefill), 추측 디코딩(Speculative Decoding) 등을 개선하여 메모리 효율성 및 처리량을 향상시켰습니다.
GPU 메모리 용량 산정 및 SageMaker AI 활용
- LLM 추론 시 GPU 메모리는 주로 모델 파라미터, 키-값 캐시, 활성화(Activations) 데이터 저장을 위해 할당되며, 모델 아키텍처 및 최적화 기법에 따라 필요한 용량이 달라집니다.
- GPT-OSS 120B 모델과 같은 대규모 모델의 경우, FP8과 같은 낮은 비트 정밀도를 사용하거나 텐서/파이프라인 병렬 처리를 통해 다수의 GPU에 모델을 분산하여 로딩할 수 있습니다.
- SageMaker AI 환경에서는
ml.g6.48xlarge또는ml.p4de.24xlarge와 같은 인스턴스에서 vLLM 및 SGLang 프레임워크를 설치하고 OpenAI API 호환 모드로 추론 서버를 구동하여 성능 테스트를 수행할 수 있습니다. - vLLM 벤치마크 도구를 활용하여 프리필, 디코드, 일반 대화 등 다양한 워크로드 유형과 동시 사용자 수에 따른 추론 성능(TPS, TTFT, ITL)을 측정하고, 인스턴스 및 프레임워크별 성능 우위를 분석할 수 있습니다.